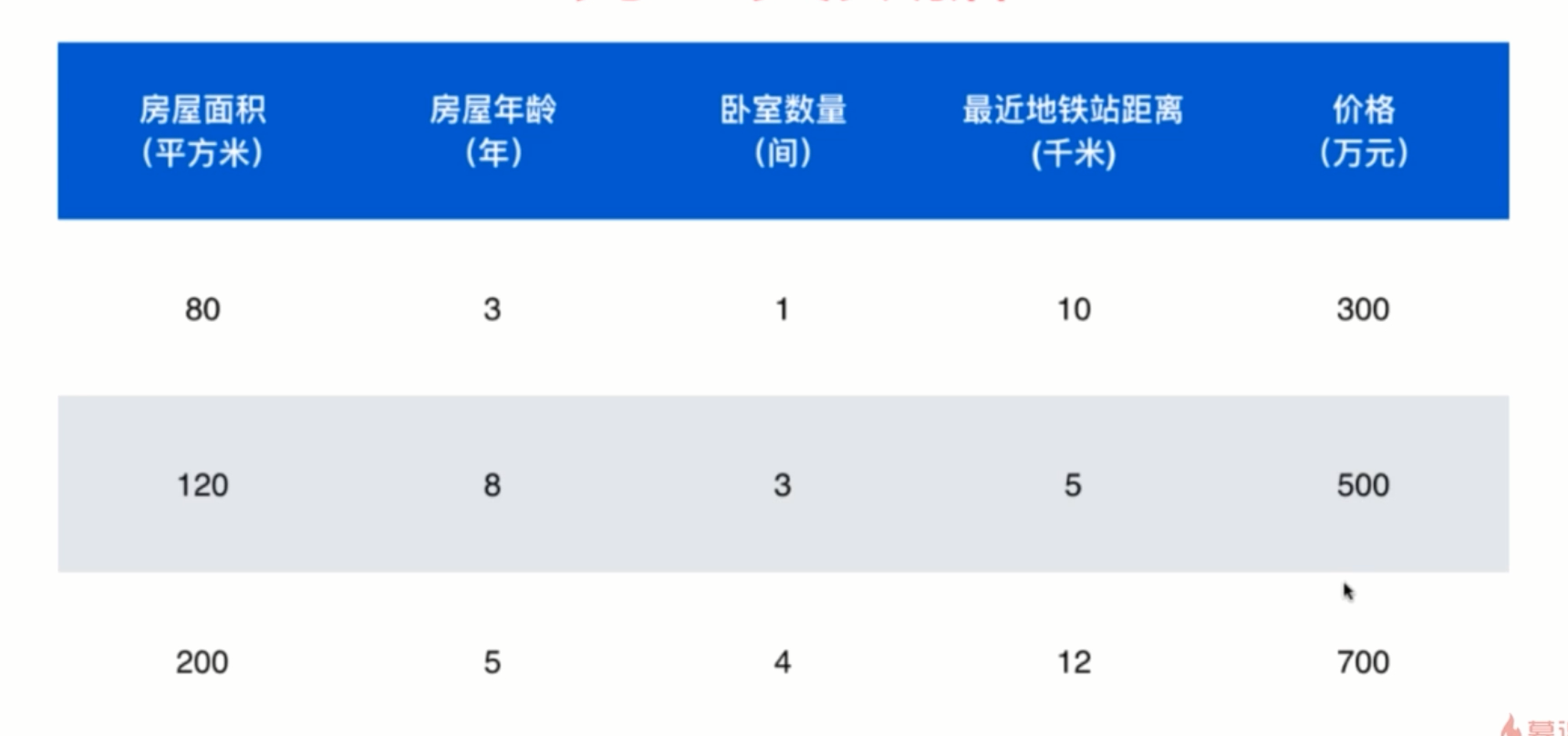
数据
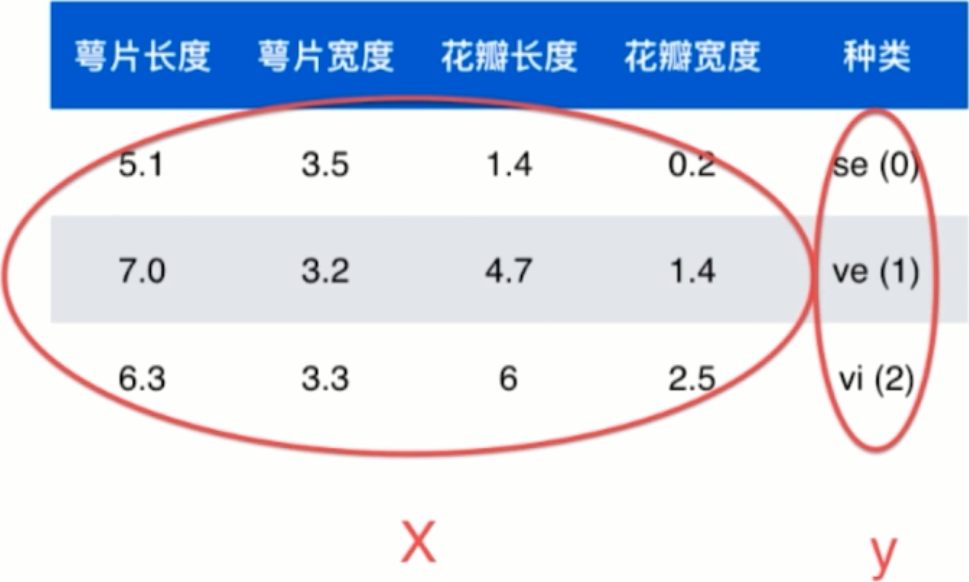 上图是一张鸢尾花特征数据表,是机器学习典型的数据集,其中含有几个重要概念:
上图是一张鸢尾花特征数据表,是机器学习典型的数据集,其中含有几个重要概念:
data set整体数据称为数据集sample每行数据称为一个样本feature除最后一列,每一列表达样本的一个特征label表中最后一列称为标记
模糊的特征
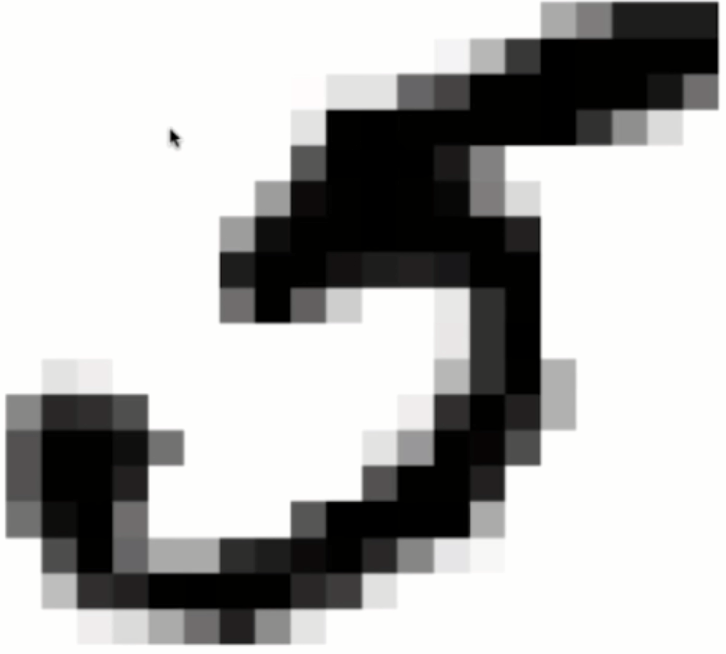
并非所有特征都如同表中如此清晰,比如mnist字符集的特征就是比较模糊的,mnist使用的28*28的像素集来表示一个数字,在这种情况下我们要存储每个像素的灰度来存储特征。
数学符号约定

特征向量符号表中第i个样本写作
特征值符号表中第i个样本第j个特征
标记符号第i个标记
表现形式
- 写程序时,用矩阵表现:
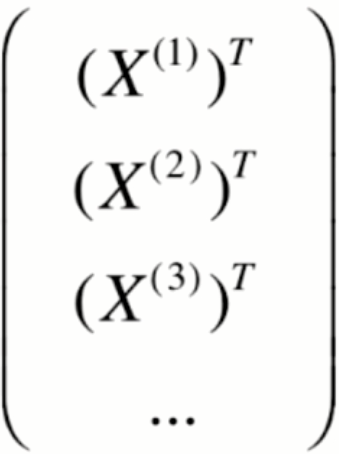
- 输出时,用图表表现:
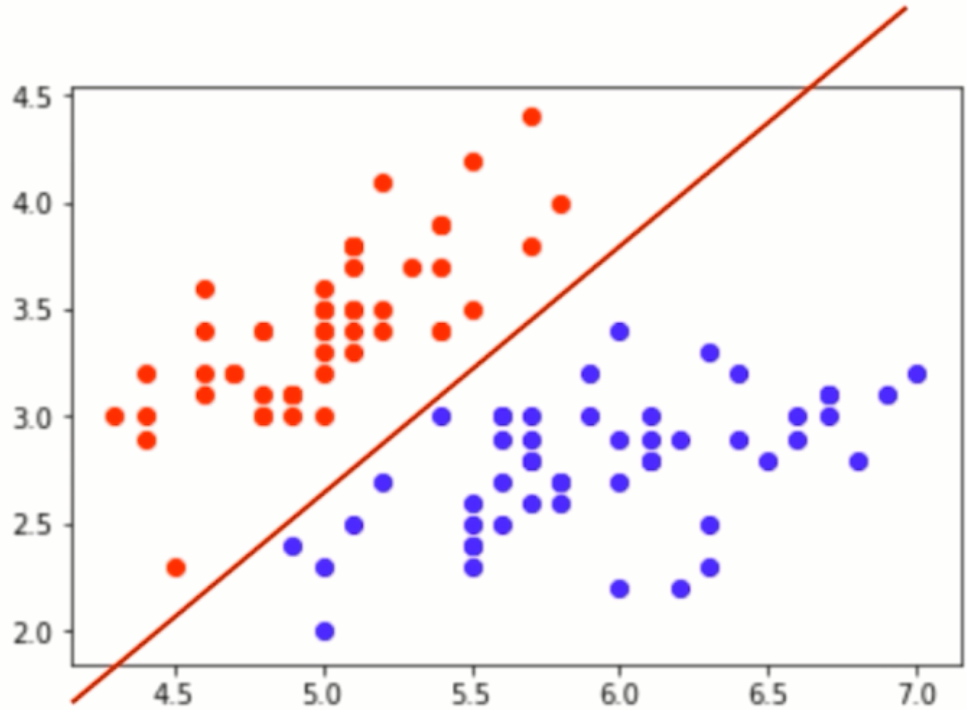
特征空间
途中将两种花用红点和蓝点标记出来,再人为的画一条线,就可以发现两种花在分割线的上下,引申出分类任务本质就是特征空间的切分。
基本任务
基本任务可以理解为机器学习到底解决什么问题?
分类任务
- 二分类-辨别一张图是猫还是狗?非1即2。
- 多分离-不只有两个类别,
mnist字符集。
回归任务
提示
当最后一列不是类别而是数值时,我们认为数据是回归任务数据集。
算法分类
监督学习
给机器的训练数据拥有“标记”或“答案”,具体算法:
- k邻近
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习
对应监督学习,给机器的训练数据没有任何“标记”或者“答案”,具体应用
- 聚类分析-网购人群行为划分
- 对数据进行降维处理,具体应用
- 特征提取-将不影响研究的特征提取并去除,减少无用特征影响和分析维度
- 特征压缩(PCA)-在损失尽量少的数据前提下,压缩数据维度
- 方便可视化
- 异常值检测
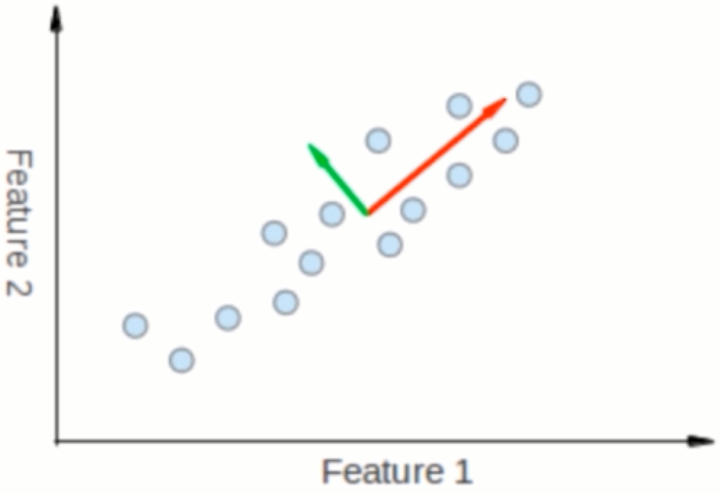
如下图PCA 将关联度较高的两个数据的关系表示为一条直线,从而通过特征1的数据即可知道特征2的数据
半监督学习
一部分数据有“答案”,另一部分没有。是现实中更常见数据,一般会用无监督学习手段对数据做处理,之后再使用监督学习手段做模型的训练和预测
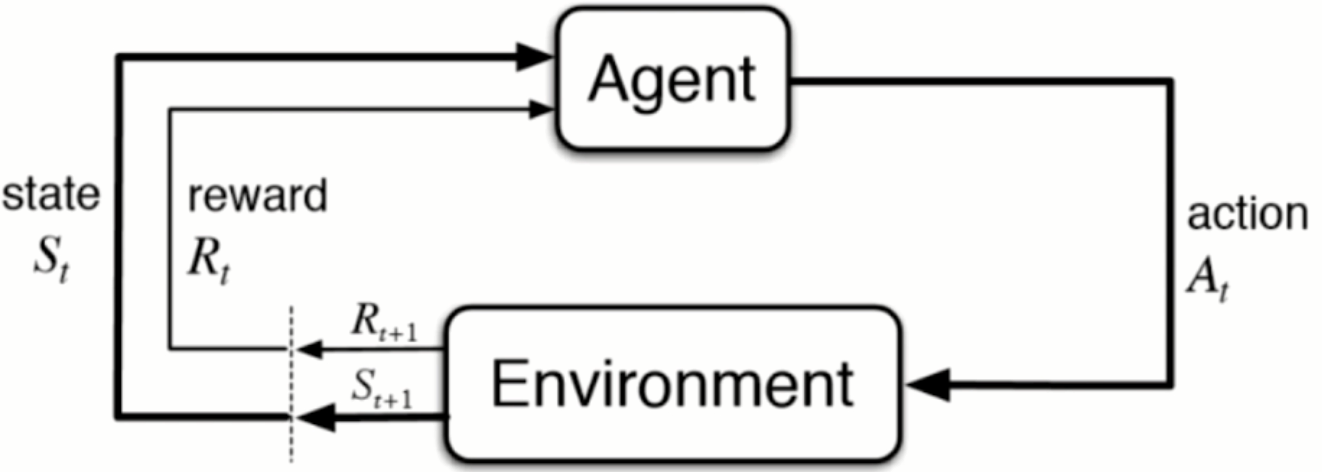
增强学习
根据周围的环境采取行动,根据采取行动的结果 学习行动方式。
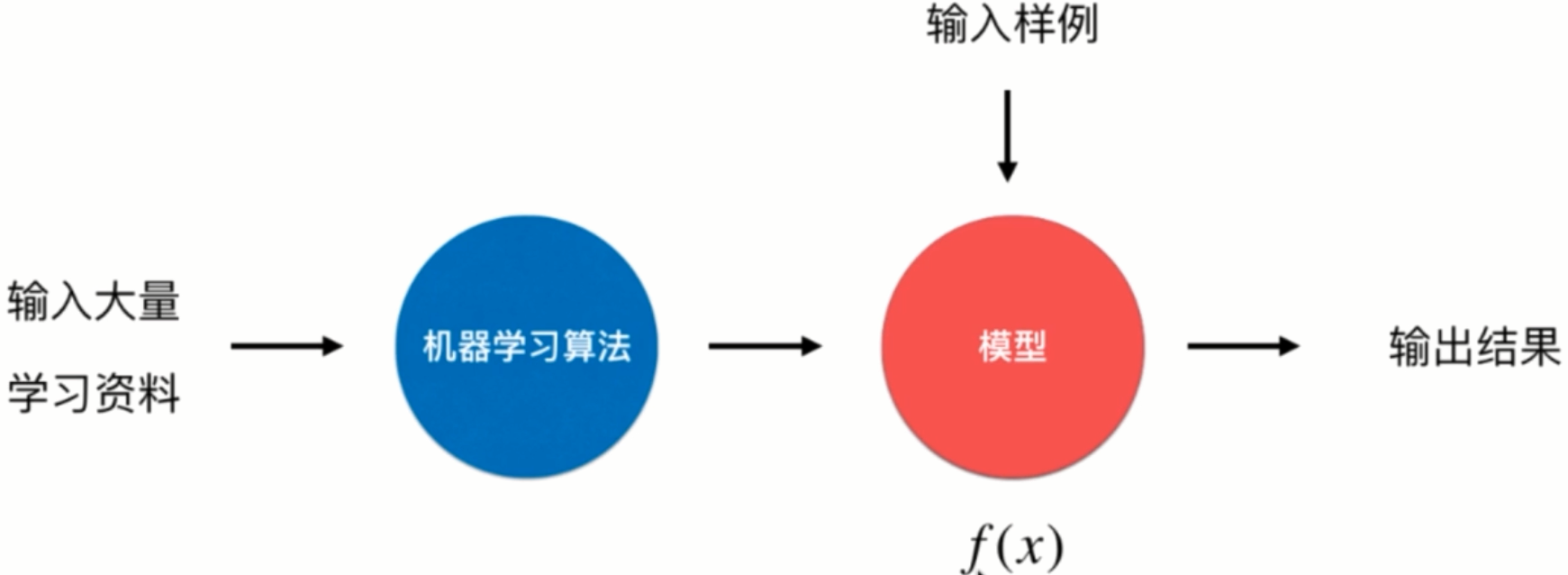
模型形成方式
批量学习
也称为离线学习,当模型形成,不会再根据输入样例更新。
- 优点:简单
- 缺点:每次环境改变都要重新学习,运算量巨大,在某些环境变化非常快的情况下,不能使用,如预算股票价格
在线学习
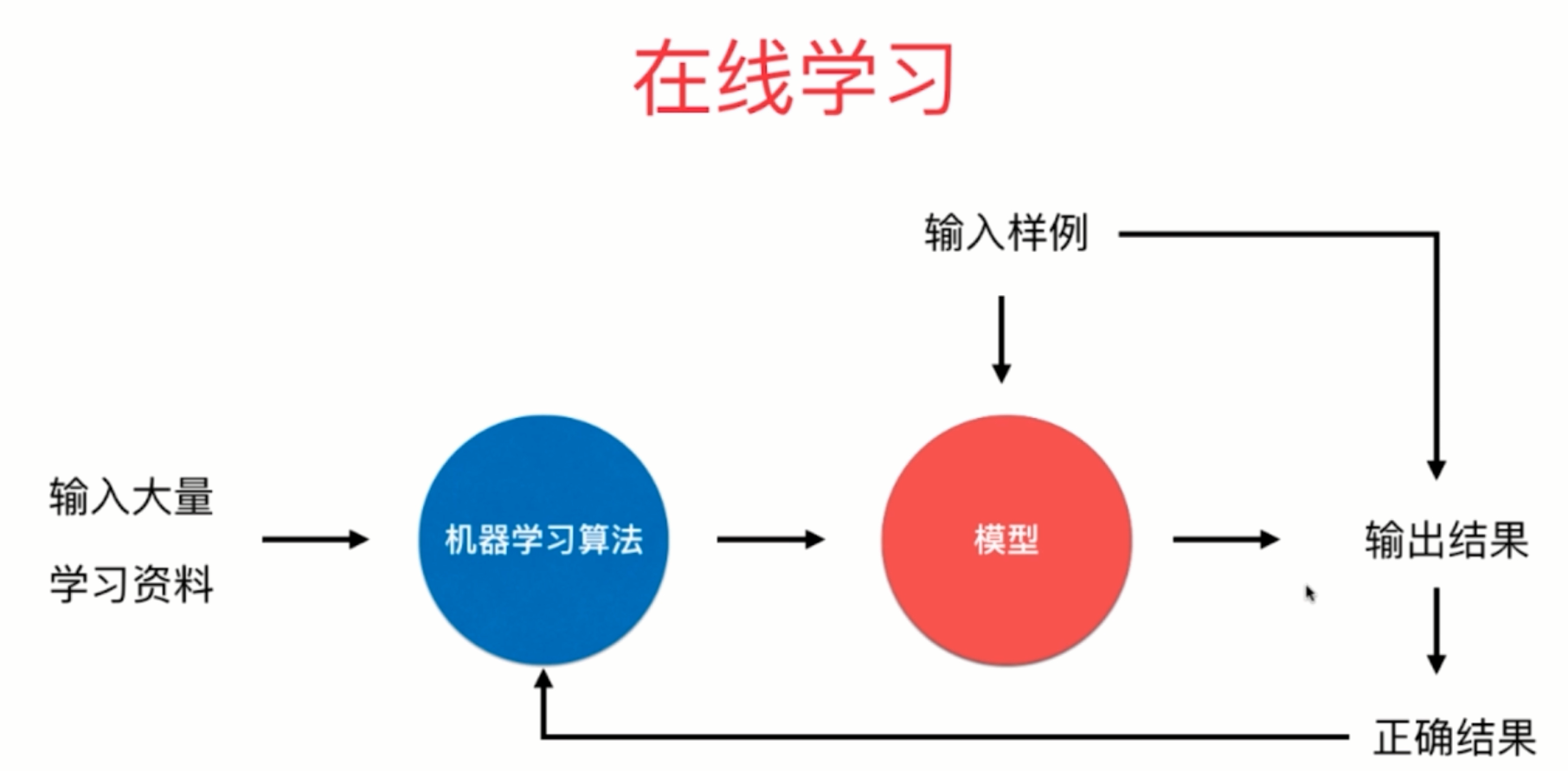
- 优点:及时反映新的环境变化
- 缺点:对数据的敏感性高,需要保证新数据的准确性
数据集假设
参数学习
特点:一旦得到了参数,源数据集将无用,如线性回归。
非参数学习
非参数学习一开始不会对数据做出假设。